开源软件的指数级增长给软件成分分析提出了新的挑战:如何实时跟踪数量庞大的开源组件并更新至自身数据集?
为应对该挑战,提升SCA分析准确性及效率,BinaryAI带来重要功能更新:后台数据集量级升级,实现版本变化实时跟踪;SCA分析结果新增组件项目地址链接。
自动化构建开源项目数据集
在以GitHub为代表的代码版本管理工具中,开发者一般会在软件代码发布新的稳定版本时打上相应的版本号,即Tag(标签),Tag如同版本库的快照,可以用于跟踪后期版本。不同版本之间,即使是两个相邻版本,也会因为增加新功能特性、修复缺陷等原因带来不能忽视的代码差异。
为了使SCA能够准确追踪定位到待检测文件所使用的开源项目的具体版本,SCA产品需要后台及时更新每个开源项目的代码仓库,以此满足用户获得软件成分清单的需求。
BinaryAI在后台自动化采集、存储来自GitHub、GitLab等不同平台的开源项目的各版本数据,并且全天候跟踪这些开源项目的版本变化。作为SaaS化的SCA服务,BinaryAI能够将后台数据的更新及时反馈到用户使用效果上。SCA结果可以定位当前分析的二进制文件所引用的开源项目名称、版本号、项目的概述信息以及该项目对应版本的源码地址链接。
分析者可通过BinaryAI分析出的引用组件信息、版本源码地址等多维度分析结果,直观梳理代码中引用的开源项目列表,准确定位版本落后、不安全的项目。
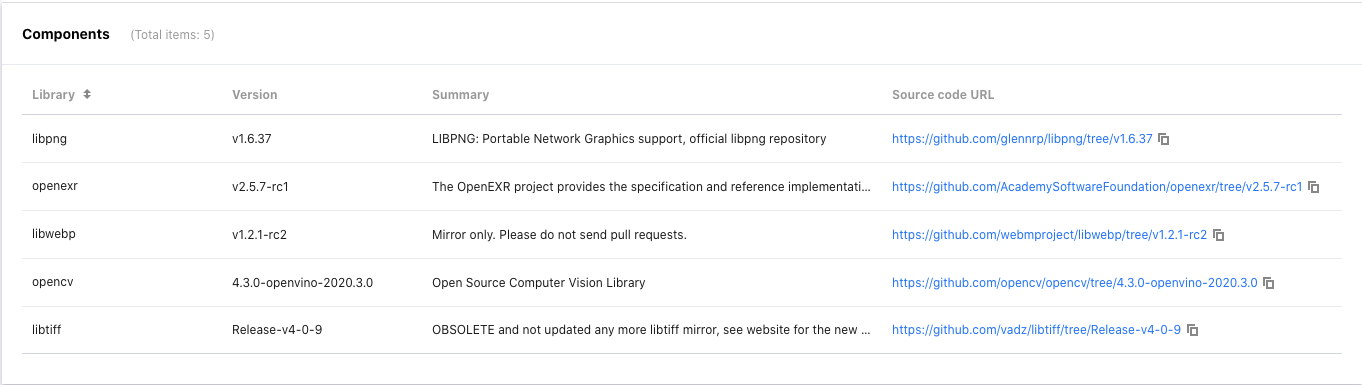
知识库持续拓展
目前,BinaryAI已经支持全网主流开源C/C++语言项目,已采集数万个代码仓库的上百万个版本,累计百亿C/C++源代码文件特征数据,大幅提升了BinaryAI知识库的广度,并且每日持续增加中,未来,BinaryAI还将继续拓宽数据来源,为SCA能力提供坚实基础。