科恩实验室自研二进制安全智能分析平台- BinaryAI技术分享:全新功能“二进制比对”的设计与实现。本文介绍了BinaryAI如何在大模型 BAI-2.0基础上叠加启发式算法,以函数粒度的语义匹配提高了复杂场景下二进制比对准确率及召回率。 体验地址:https://www.binaryai.cn
科恩实验室在2021年8月首次发布二进制安全智能分析平台—BinaryAI,BinaryAI可精准高效识别二进制文件的第三方组件及其版本号,旨在推动SCA(Software Composition Analysis,软件成分分析)技术在DevSecOps、威胁情报、安全研究等应用场景发展。
二进制可执行文件比对是计算机安全的经典问题,通过比对两个二进制文件的异同,即使源代码不可用,也能够进行程序版本变更分析及第三方组件识别等任务。但现有工具大多依赖于人工选定的特征,对函数语义理解不足,在跨版本或优化级别的复杂场景下识别效果不佳。
科恩实验室凝聚多年“AI+算法”研究成果经验,推出函数相似度匹配模型 BAI-2.0(BinaryAI全新代码匹配模型BAI-2.0上线, “大模型”时代的安全实践),并在此基础上叠加启发式算法,实现了BinaryAI最新的二进制文件比对功能,以函数粒度的语义匹配提高了复杂场景下二进制比对准确率及召回率。
该功能底层比对算法代码现已开源,欢迎复现:https://github.com/binaryai/bindiffmatch 平台比对功能体验传送门:https://www.binaryai.cn/
四大使用场景
(1)比较新老版本软件功能变更 软件迭代代码变更有限,在面对新老版本时,可以迅速识别并排除相似的部分,从而集中精力在变更的函数上。
(2)识别组件库的使用情况及风险 分析大型程序时,处理集成的开源组件代码需要花费大量精力。手动构建带有符号信息的开源库程序,并借助二进制文件比对技术匹配函数以完成符号标注,可以快速理解程序的局部逻辑,形成对程序整体结构的认识,有助于进一步分析核心逻辑和组件可能引入的安全缺陷、许可证问题等。
(3)鉴定软件抄袭侵权 在无法获得源代码的场景下,通过二进制文件比对也可以判断待测程序是否与已知程序雷同,可以用于版权调查或者剽窃抄袭判定。
(4)分析恶意软件变体 同一家族的恶意软件在实现上会有一定的共同特征。通过二进制文件比对可以将相似的样本归类,有利于找到具有类似行为的恶意软件变体。
二进制比对相关工具及研究
目前工业界和学术界有大量针对二进制比对任务的工具及研究,几个有代表性的工作如下:
BinDiff
BinDiff[1]是zynamics团队开发的产品,可以和IDA、Ghidra、Binary Ninja工具结合使用,对两个二进制文件执行细粒度的比对。BinDiff采用的是基于图结构(控制流图和调用图)的匹配以及若干启发式特征匹配技术。截至目前,BinDiff的最新版本为2021年发布的7.0版本,其特征导出模块BinExport已经开源。
Diaphora
Diaphora[2]是一款流行的开源二进制比对工具,目前仍在积极维护中,最新版本为上月发布的3.0版本。其分析过程分为两个阶段,第一阶段:作为IDA Script运行,导出文件和函数的各种特征存入数据库;第二阶段:可以作为IDA Script运行或者离线运行,在导出的特征上运行各种策略(heuristics),最终生成完全匹配、部分匹配、无法匹配的函数列表。匹配结果导入IDA后,能够以函数、伪代码、汇编、调用图等多种粒度展示。
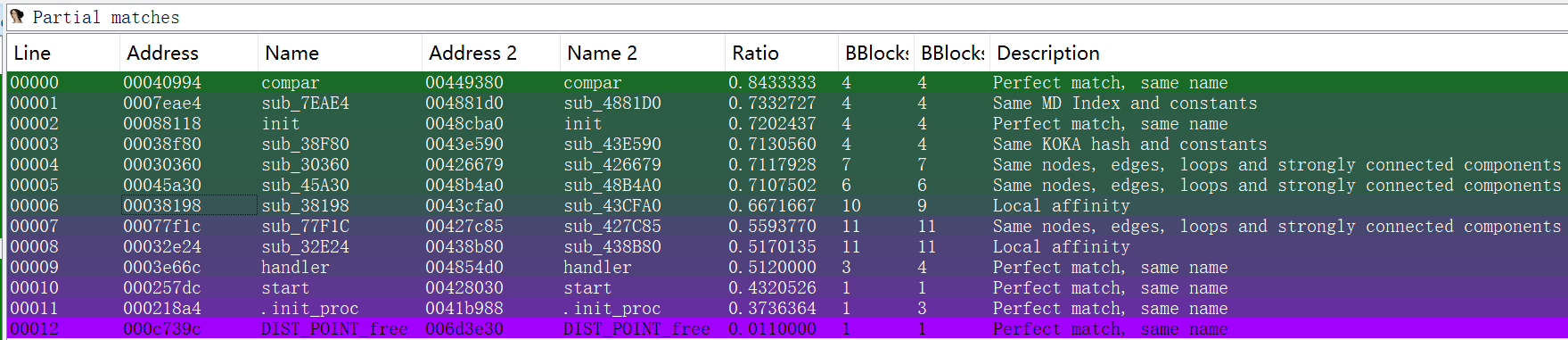
Diaphora的核心能力在于其策略,这些策略大多是基于人为选定的特征,用于判断单个函数的匹配性,例如"Same KOKA hash and constants"、"Same nodes, edges and strongly connected components"等。此外,Diaphora还包含少量实验性质的文件级别特征,例如“Call address sequence”等。
DEEPBINDIFF: Learning Program-Wide Code Representations for Binary Diffing
这是发表于2020年的论文[3],特点是可以在整个二进制文件上执行基本块级别的比对。作者应用了机器学习自然语言处理技术,结合汇编指令和控制流图结构为每个基本块生成一个embedding向量,然后结合图结构,通过迭代寻找匹配的基本块。相比于先前的同类工作,DEEPBINDIFF取得了较大的效果提升,但缺点是它受编译条件影响较大,对于基本块和控制流结构敏感,对跨架构支持不足。
对以上工具/研究及BinaryAI最新比对算法进行简单的对比:
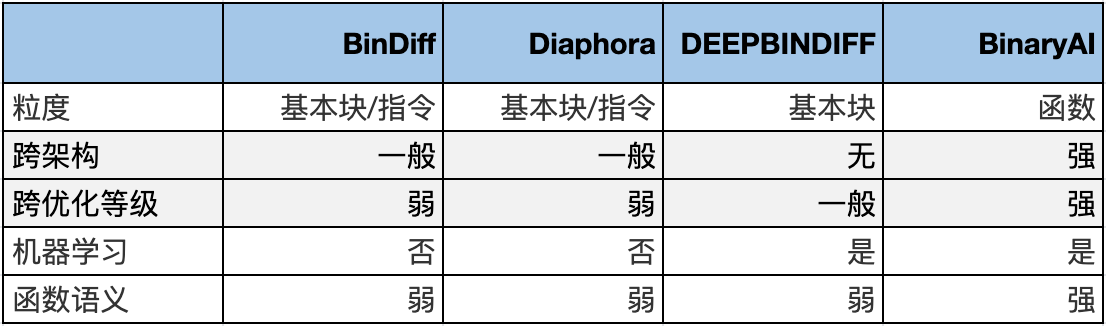
总的来说,目前现有的二进制比对工具/研究存在以下共性问题:
1.很大程度上依赖特征工程,这意味着人工介入较多。
2.在信息提取和嵌入方面主要关注汇编指令或控制流等低层次特征,对函数的语义逻辑体现不足。当架构、优化级别、版本相差过大时,将难以保证匹配效果。
比对功能算法设计
两个二进制函数是否匹配,应当以它们的逻辑是否相同来定义。然而,现有的很多工具主要基于传统特征工程来判断函数的�相似度,例如基本块、指令序列、字符串等低层次语义特征或者控制流图等函数内的结构特征。这些方法在分析局部代码微小修改方面较为有效,但涉及到不同编译器、优化选项、指令架构等情况时,即使是同一份源码,低层次特征也可能存在巨大差异,从而导致难以准确匹配。此外,当匹配范围从单一函数扩展到整个二进制文件时,函数内部的细节特征对全局的直接影响较小,而函数自身的相似性以及函数间的关系等宏观特征变得更为重要。
基于上述分析,科恩实验室将函数作为匹配的最小单元,以函数的语义相似度作为基础,同时结合函数间的关系,实现了BinaryAI的二进制文件比对功能。
大模型生成向量体现语义级函数匹配
判定两个函数是否匹配,可以从语法形态和语义逻辑两个角度考虑。基于语法形态进行判定简单直接,例如只有当两个函数具有相同的语句序列或控制流图时才会判定为匹配,虽然此类特征容易提取,但是由于编译过程对语法结构进行了大量变换,只有很少的情况能够保证两个函数的语法形态特征完全匹配;
基于语义逻辑进行判定则更接近本质,只要两个函数的功能一致就认定为匹配。在实际应用中,基于语义逻辑匹配具有更高的应用价值,但是语义逻辑等价本身是一个不可判定问题。
常见的二进制比对工具(例如Diaphora)通常是预先提取若干人工选定的函数特征(例如某些特殊的指令序列),然后运行一些启发式策略判定函数是否匹配。这些策略大都基于一个假设:两个函数如果具有足够的可匹配语法形态特征,那么它们的语义逻辑应该也是一致的。然而,编译过程的不确定性会导致相同的语义逻辑有无数种可能的语法形态,这个假设很多时候是无法成立的,因此此类工具在复杂条件下进行语义匹配的表现并不理想。
但是,基于AI大模型,我们可以绕开这层假设,直接将函数的语义是否相似作为原始信息提供给模型做训练。依靠大模型强大的内在特征提取能力,经过学习后模型产生的输出就能够直接蕴含函数的语义信息。具体应用到比对任务时,两个输出的embedding向量之间的距离即可反映函数的语义相似性。
BinaryAI后台有持续更新的海量C/C++开源项目数据作为语料,在此基础上训练得到的BAI-2.0大模型生成的embedding向量能够很好地体现函数在真实场景下的语义,为BinaryAI二进制文件比对功能提供了基础能力。
大模型加持下的文件匹配
一个二进制文件可以看作多个函数的集合,文件匹配的目标是找出两个二进制文件中所有能够匹配的函数对。
在人工做函数匹配的过程中,通常需要在反编译器中打开两个文件,寻找具有明显特征的函数(例如带有特殊的字符串),如果它们的伪代码相似度也非常高,就先把它们标记为初始匹配。然后,从已经标记的函数开始,观察它们调用或被其他函数调用的情况,可以认为这些函数也是大概率匹配的。最后,剩余的函数需要依靠人工判断,是一个比较困难的任务。
整个过程结合了函数自身的相似性以及函数之间的关联关系。由于人工判断函数的相似性是一个比较困难的任务,所以第一阶段能找到的初始匹配往往很少或存在错误,这会阻碍第二阶段利用函数关系找到更多扩散匹配,并进一步导致第三阶段剩余更多难以判断的函数。
BinaryAI的二进制文件比对功能在流程上与人工匹配的过程相似,同样分为初始匹配、扩散匹配、剩余匹配三个阶段。
(1)初始匹配
依靠BAI-2.0模型的embedding能力,我们可以为每个二进制函数生成一个向量作为函数特征的表征,通过直接使用两个向量间的余弦相似度即可判断两个函数之间的相似性。
在初始匹配阶段,需要保证高准确性的前提下尽可能找出更多的匹配函数。然而,简单的贪心策略容易出现重复选取和漏选的情况。因此,我们采用全局视角,将其转换为完全二分图的最大匹配问题。完全二分图的两组节点分别为两个文件的所有函数,边的权值为两个函数的向量余弦相似度。这可以确保匹配结果中不存在重复的函数,并且让相似度不是最高的函数也有机会被选中。
获得完全二分图的最大匹配之后,需要进行进一步的筛选。其中,筛选条件之一是两个函数必须都是有效函数,导入表、导出表、Thunk等包装函数以及过于简短的普通函数都被视为无效函数。筛选条件之二是相似度大于阈值。此阈值应设定为较高的值,以确保第二阶段的需要。筛选需要放在最后进行,这样二分图匹配才能具有一个文件的全局视角。
(2)扩散匹配
第一阶段只利用了函数自身的相似性找到置信度最高的匹配。第二阶段则利用一个文件内函数间的关系,继续扩展第一阶段的匹配结果集合。
一个二进制文件由多个函数组成,函数虚拟地址的排布顺序构成了位置关系, 函数之间的相互调用构成了调用关系。这两种关系在二进制文件比对中有重要作用。
调用关系的作用基于一个假设:如果两个函数逻辑相同,那么它们往往具有相近的数据流和控制流,甚至源代码实现可能也比较接近,它们各自调用的其他函数也大致相同。位置关系的作用基于一个现象:一个源代码文件作为一个独立的构建单元,其中的函数在二进制文件中通常会聚集并保持顺序。
实际情况下,位置关系的作用是否成立非常依赖于编译器的具体行为,例如,如果开启了链接时优化,编译器可以对函数做全局重排;同时,函数内联或者隐式生成的函数都会打破位置关系的假设等;这使得位置关系在跨编译器等更广泛的二进制比对场景中更难被利用。相比之下,调用关系主要基于函数逻辑假设,且二进制比对场景的两个输入文件通常会有相关性,因此调用关系相比位置关系更加稳定,适用范围更广。
所以,本阶段主要基于函数间的调用关系:以第一阶段的结果为中心,对每一对匹配的函数,找到它们各自在函数调用图上邻近的节点,在这两组节点中寻找最大二分图匹配,过滤掉相似度过低或无效的函数作为新的一轮结果。然后,以上一轮的匹配结果为新的中心,重复此过程,继续沿着调用图继续扩散寻找新的匹配节点,直到无法找到更多匹配为止。
(3)剩余匹配
在前两阶段完成之后,第三阶段将在剩余的未匹配函数上再次进行二分图最大匹配。由于剩余函数集合规模远小于全集,因此可以应用比第一阶段更宽松的相似度阈值进行过滤,这一阶段作为对前两阶段的补充,旨在提高整体的召回率。
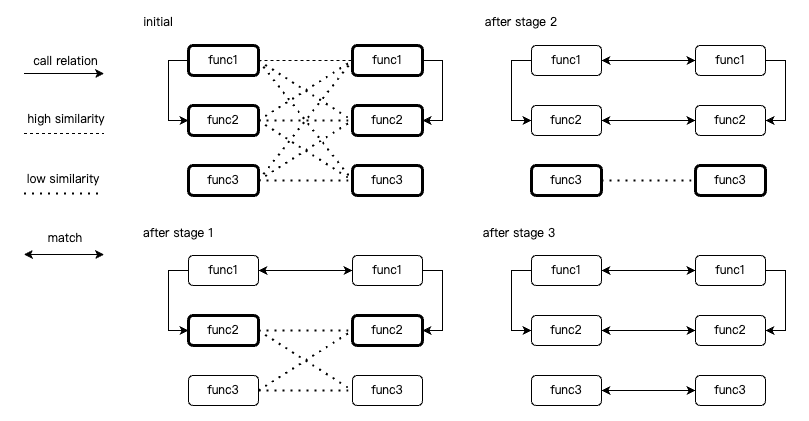
下图是三个阶段的简单示例:假设两个文件各有三个函数,初始时两两之间的相似度分数已知。
- 第一阶段全部函数都参与匹配,初始匹配结束后,只有两边的func1由于相似度分数非常高满足过滤条件被保留;
- 第二阶段只在func1调用图上的邻近函数之间寻找匹配,因此选定了两边func2作为匹配,由于没有更多与func2调用关系邻近的函数,第二阶段结束;
- 第三阶段只在前两个阶段都没有选中的函数之间寻找匹配,最终召回了两边的func3匹配;
比对功能算法评测结果
数据集
统计评测数据集:选用DEEPBINDIFF论文的数据集[3],即coreutils、findutils、diffutils三个library,每个library分别在若干个不同版本、每个版本在不同的优化级别下编译,并去除符号表;然后,按照”相同library+不同版本+相同优化级别”和“相同library+相同版本+不同优化级别”分为两组,每组对同名的二进制文件做比对。
样例评测数据集:选用openssl库作为样例,分别选择1.1.1u版本以O0优化级别编�译为arm架构、3.1.1版本以O3优化级别编译为x64架构,并去除符号表,将产出的openssl可执行文件做比对。openssl作为最成熟的加密算法库之一在各类项目中被广泛应用,而且不同环境下使用的版本、编译选项、指令集架构等有显著差异,这为二进制文件比对任务带来了更大的挑战。
评测指标
本文将以下三类函数定义为无效函数:
(1) 无法被Ghidra正常反编译的函数(即使出现在函数表中)
(2) Thunk函数(无实际功能,只转移控制流到另一个函数)或者指向导入表的外部函数
(3) 反编译后伪代码行数小于等于7行的小函数(因为这些函数通常不会引起人们的过多关注,且它们包含的特征往往不足以做出有效的区分)
对于先前构造的groundtruth中的匹配,只有两个函数都是有效函数时才计入groundtruth_matches集合,作为后续统计的总量。
对于待测工具输出的匹配,如果两个函数都是有效函数且属于groundtruth_matches集合,则是正确的匹配,记为correct_matches集合;如果两个函数都是有效函数但不属于groundtruth_matches集合,则视为明确错误的匹配,记为wrong_matches集合;如果任何一个函数属于无效函数,则忽略此匹配结果,不计入正确或错误的统计。
基于上述定义,评测采用三个数值指标:precision、recall、F1 precision:准确率

recall:召回率

F1:precison和recall的调和平均

数据预处理
(1) groundtruth的构建
当某个库选入测试集后,首先对源代码修改编译选项以在构建产物中保留符号表,然后正常运行构建流程,得到原始的构建产物;然后对二进制文件进行符号剥离,得到对应的无符号二进制文件;下一步,将剥离前后的两个文件分别传入Ghidra反编译器,导出各自的函数列表文档;最后,从有符号二进制文件的文档中提取函数名,补充到无符号二进制文件的文档中。
后续进行任何比对都只在剥离符号的文件中进行,使实验更贴近真实场景,且避免比对工具利用函数名做辅助判断。做不同文件比对时,只要函数名称相同就标注为匹配。因为函数名通常是对函数功能的概述,相同名称的函数即使源代码不同,语义逻辑大概率也是相近的。
(2) Diaphora匹配结果的构建
使用IDA Script加载Diaphora,评测时只额外开启relaxed_ratio选项,其他保持预设的默认值。因为比对任务的目标是找出匹配的函数,因此函数自身的微小改动不会被当做首要关注点。
构建过程分为三步。
1、使用IDA headless mode加载Diaphora script导出其特征sqlite文件;
2、使用离线Diaphora script对两个sqlite生成Diaphora匹配结果文件;
3、将结果文件转换为统一格式;
本文的测试数据使用IDA7.5+Diaphora3.0生成。
(3) BinaryAI二进制文件比对算法匹配结果的构建
需要额外调用BAI-2.0模型为每个函数生成embedding向量,BinaryAI开源仓库 中已包含此数据。
评测结果
(1) 统计评测:coreutils、findutils、diffutils,cross-version和cross-optimization-level汇总(去除符号)

(2) 样例评测[4],openssl-1.1.1u-gcc_arm_O0-openssl.strip和openssl-3.1.1-gcc_x64_O3-openssl.strip (去除符号)

下图分别是Diaphora和BinaryAI对这两个文件的部分匹配结果�(注:为便于直观判定匹配的准确性,图示结果使用了保留符号的二进制文件,并在Diaphora的配置中选中"Ignore all function names"、"Relaxed calculations of different ratios"以及"Use slow heuristics"),可以看出Diaphora的匹配结果中函数名存在不一致的问题,即产生了误报。
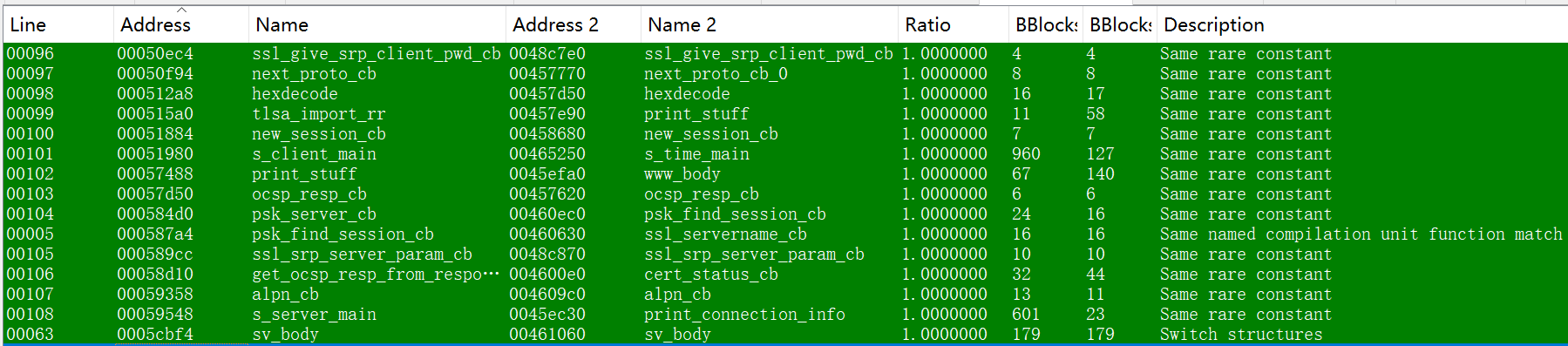
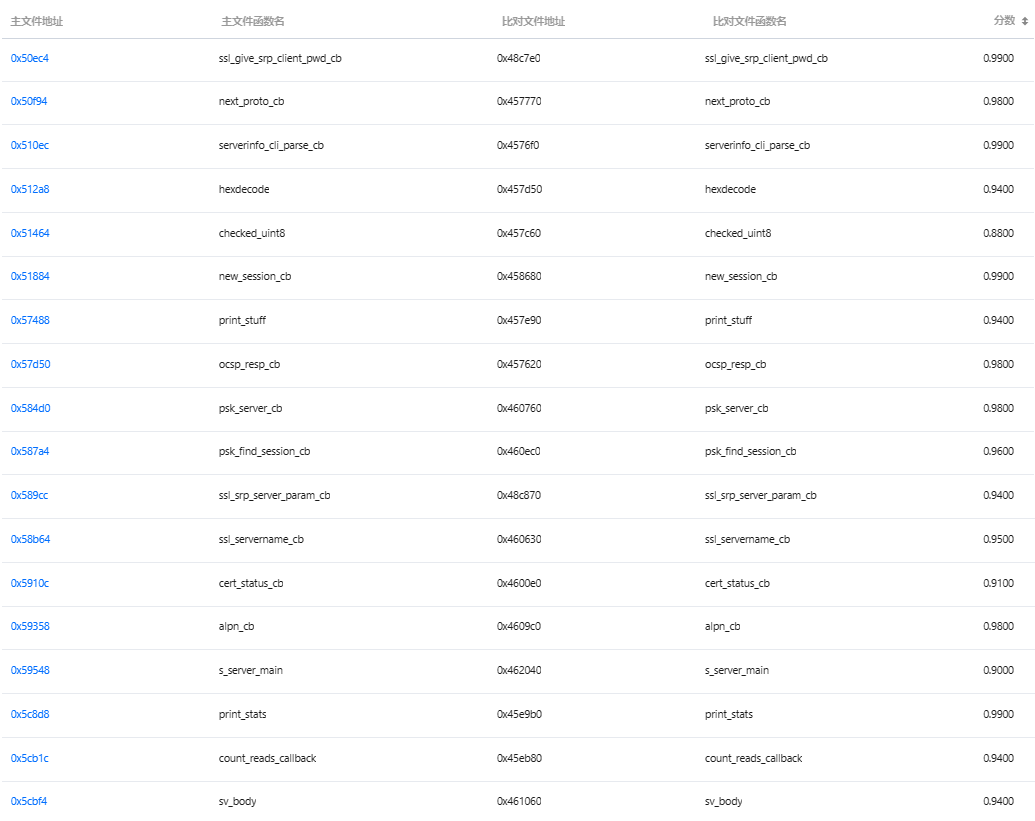
通过两组评测可以总结出,以大模型BAI-2.0 embedding为基础能力的BinaryAI表现较稳定,优于Diaphora。
总结
二进制文件比对在实际场景下具有重要的应用价值。现有工具无论是基于传统的启发式特征工程还是汇编语句级别的机器学习模型,在识别的准确率、召回率方面都尚未达到理想的状态。
科恩实验室多年来旨在实现各类技术的纵深融合,BinaryAI作为科恩将AI赋能安全的应用实践,本次依托自研BAI-2.0大模型,着重于语义匹配,实现了二进制文件比对更为优秀的解决方案。在处理跨架构、版本、优化级别等复杂场景下,能够取得更好的评测效果。
目前,BinaryAI的二进制比对功能已经全面发布。欢迎各位前往 https://binaryai.cn/选择“自定义比对功能“开启体验。此外,如有复现评测结果需求,请前往BinaryAI官方仓库https://github.com/binaryai/bindiffmatch获取相关资源。
Reference
[1] BinDiff:https://www.zynamics.com/bindiff.html
[2] Diaphora:https://github.com/joxeankoret/diaphora
[3] DEEPBINDIFF:https://github.com/yueduan/DeepBinDiff
[4] BinaryAI示例文件